
Similarity Search
Video Recap
- Navigate to Datasets tab - This can be found on the sidebar from the project homepage.
- Navigate to the query image you want to search with - This can be done with metadata query, scrolling through the Datasets page, or searching for the filename directly.
- Select Similarity Search from the dropdown next to the query image - The dropdown can be found from the vertical
...button at the bottom right of the image. - Congratulations, you should have up to 100 relevant images rendered in order of feature similarity!
Similarity Search on Nexus
Similarity search is currently only supported for images and not videos! Please Contact Us if you have use cases that require more support!
By following the above instructions, you can easily search for similar images. To see whether the tool is ready, you can check the icon on the upper left, right below the image upload area. It should be purple if the embeddings have been calculated, and you will receive a notification as well. If not, the symbol will be grey and the notification will show that the process is still ongoing.
What is Image Similarity Search?
Image similarity search is an asset management tool that allows users to search through an image dataset for similar or dissimilar images using a query image. The recent development of foundational computer vision models has aligned well with the task of image retrieval, due to their use of embedding architectures to construct uniformly sized vectors from images. Transformer architectures such as CLIP (developed by OpenAI) and DINOv2 (developed by Meta Research), have met the most success both in academic benchmarks and practical settings. This is due to their inherent generalizability and ability to capture visual and semantic details within comprehensible vectors, effectively transforming millions of pixels into a list of less than a thousand numbers.
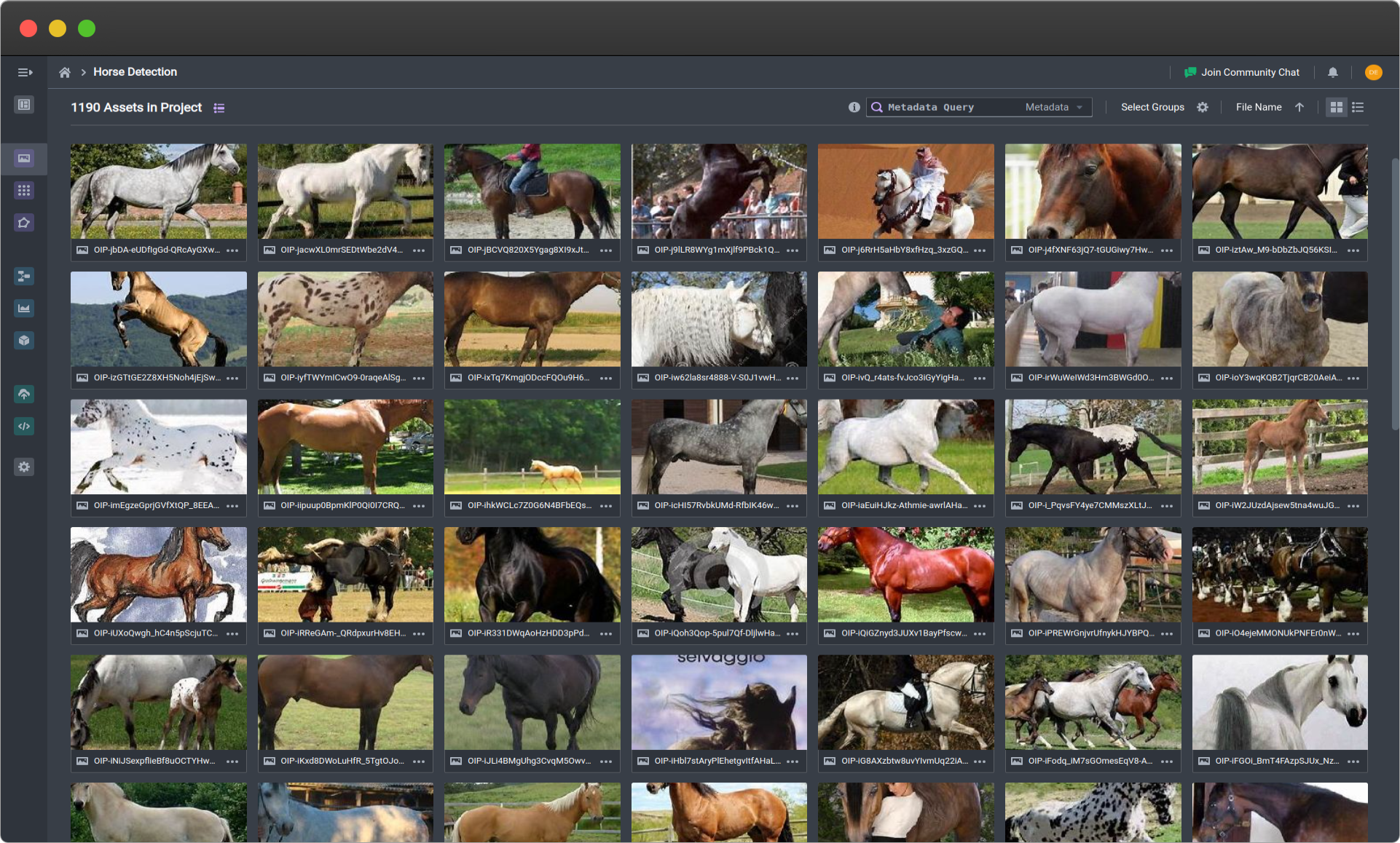
Example dataset of horses (click image to expand)
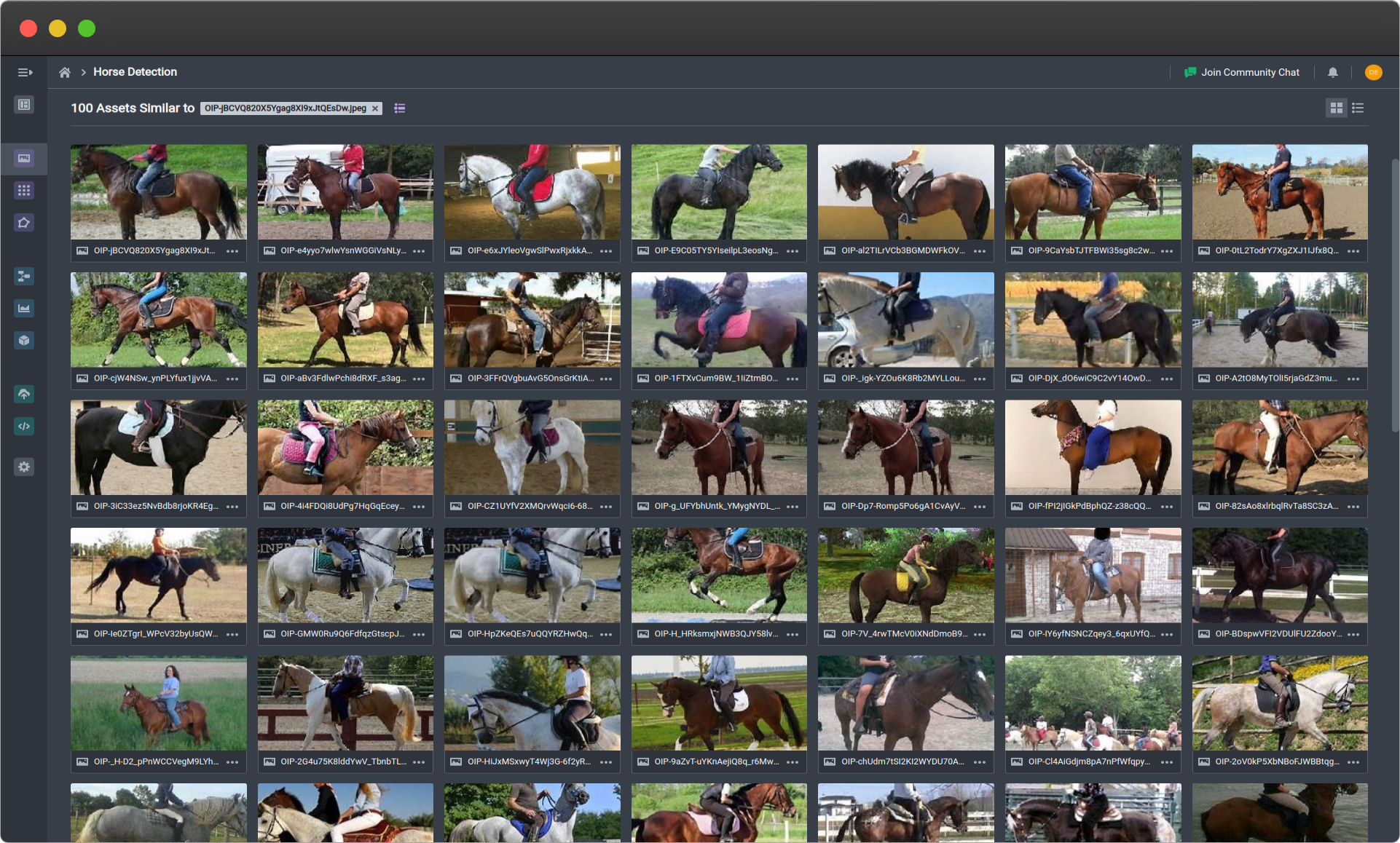
Using Similarity Search to find all horses with riders. Query image is the first image on the top-left .
General Approach
Assets in a dataset will have corresponding embedding vectors generated. These vectors will then be the source of comparison. When a user selects a query image and requests for the most similar/dissimilar images, the associated query vector will be compared with all the other vectors in the dataset, and sort the dataset in such a way that images corresponding with the closest/farthest vectors are rendered in that order.
Image Embedding Architectures
The two architectures that we considered were CLIP and DINOv2, which are both vision transformer architectures, but trained with different datasets and with different methods. As these are the two state-of-the-art models in the space, we compare them in several factors in our use case.
Architectural Design
They are largely focused on utilizing a vision transformer with an encoder and decoder with multiple heads which can be adapted for several tasks. CLIP also contains experiments for smaller architectures such as ResNet-50. They typically offer models of several sizes, from ViT-S, ViT-B, ViT-G, etc. to accommodate various scales and levels of details.
DINOv2 and CLIP loss functions also differ. DINOv2 uses image-level and patch-level objectives with the weights untied, and uses Sinkhorn-Knapp centering as well as a KoLeo regularizer to construct a more uniform span in the features, thus, making the features more distinct from each other, and allowing for more granularity.
CLIP loss functions are focused on maximizing cosine similarity between text and image pairs and minimizing cosine similarity between the incorrect text and image pairs. The cosine similarity is calculated from embeddings developed from image and text encoders.
Training Methods
CLIP is trained on a dataset of paired data of a caption and the image itself. DINOv2 is trained through self-supervised settings with an incredibly large dataset as compared to the fully supervised CLIP. DINOv2 also utilizes knowledge distillation from its larger models to achieve stronger performance but with fewer parameters, thus condensing foundational model performance in more accommodating model sizes.
Choice of Similarity Metrics
There are a wide variety of distance metrics that can be used to quantify how similar two vectors are. Common distance metrics are the L2 or Euclidean distance and cosine similarity. While Euclidean distance is a more prototypical metric for a broad class of tasks, embedding vectors such as ones generated by CLIP and DINOv2 are incentivized in their ambient space to be closer based on cosine similarity if their features are similar. As such, our search also relies on cosine similarity calculations to order the images during a search.
Cosine similarity is calculated as below, where A and B are arbitrary embedding vectors, and the resulting cosine similarity varies from -1 to 1, where intuitively, -1 means that the embedding vectors are opposite in concept, 0 meaning they have no relation, and 1 being that they are exactly the same. When users search for the most similar images, the cosine similarity is ranked from highest to lowest, and when searching for the least similar, the cosine similarity is ranked from lowest to highest.
Based on the above criteria, we determined that DINOv2 was more capable of storing important visual details for a broader range of data without being swayed by attempts at semantic understanding that CLIP might attempt to encode. As such, we are utilizing DINOv2 as our underlying image embedding model for search.
What is Similarity Search Used For?
In cases when users want to leverage the more intangible visual attributes within the image data itself to dig deeper into their dataset, similarity search is the more appropriate tool. Similarity search aims to target use cases such as trying to see if there are other similar images when an anomalous image appears in a large dataset that has recently been brought in, and there hasn’t been enough time or resources to manually work through the dataset. For example, in an MLOps workflow that leverages active learning, when anomalous images in production are re-uploaded to the platform, one can use similarity search to see if any other images in the dataset are visually similarly anomalous and simply were not identified earlier.
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
Updated 10 months ago