
Model Training on Runners
Selecting Your Self-Hosted GPU Runner for Training
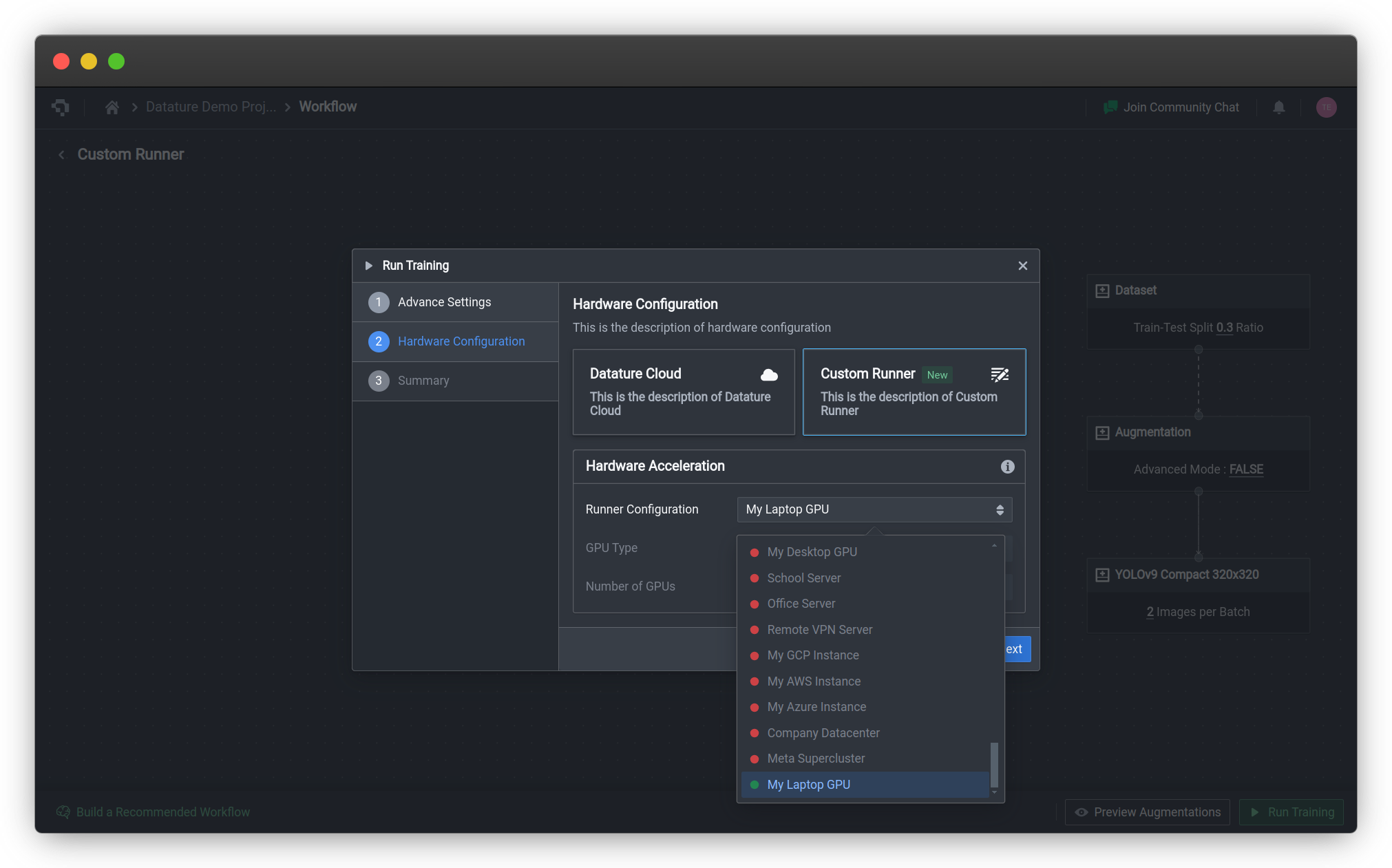
Once your Runner has been set up, you can build a workflow. You can run the workflow by clicking the green Run Training button on the bottom right corner of the Workflow screen, which will bring up the Training Settings menu. After you've configured the advanced settings comprising the Checkpoint Strategy and Advanced Evaluation, you can select your Runner from the drop-down list under the Hardware Acceleration section. The different statuses of the Runners are outlined in the table below.
| Symbol | Runner Status |
|---|---|
| 🟢 | Online - runner is available and can accept new training jobs.. |
| 🟠 | Suspended - runner is available but cannot accept new training jobs. |
| 🔴 | Occupied - runner is currently running a training job and cannot accept new training jobs. |
You will only be able to select Runners that are online 🟢 to run your new training. If no Runners are currently available, you may need to wait for one to become available again before starting your training.
Currently, only NVIDIA GPUs are supported. If you wish to run training on other GPUs or CPUs, please contact us for support.
The GPU Type and Number of GPUs will be inferred based on the GPUs on your system.
Monitoring and Evaluating Model Trainings
To evaluate and monitor your live training, you can actually follow the same setup for typical model trainings on Nexus. We provide a live dashboard to monitor metrics as well as advanced evaluation tools to better understand your trainings. To learn more, check out how you can evaluate your model performance.
Model Compute Requirements
| Model Architecture | Min. / Recommended CPU RAM | Min. / Recommended GPU VRAM |
|---|---|---|
Common Questions
Why Has My Compute Minutes Quota Decreased Even Though My Training Run Was Killed?
The Runner will automatically kill a training run if it cannot establish a connection with Nexus, some scenarios include regeneration of secret keys, prolonged network connectivity issues, and uninstallation of Runners while training runs are still ongoing. Our retry mechanism has a timeout of 15 minutes in place so that training runs are not accidentally killed due to brief lapses in connectivity. This will be factored into the consumption of compute minutes.
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
Updated 10 months ago