
Post-Training Quantization
What is Post-Training Quantization?
Quantization converts tensors in a pre-trained model, specifically weights and biases, into a lower-precision format such as floating-point values with 16 bits of precision (FLOAT16), or integers with 8 bits of precision (INT8). This helps to compress the model size and reduce computations in the forward pass during inference, which increases compatibility and boosts model performance on resource-constrained edge devices.
How to Quantize Your Trained Model
You will first need to train a model on Nexus. Once that’s done, navigate to the Artifacts page where you can view the model checkpoints that have been saved. When you have chosen the model checkpoint you wish to export, click on the three dots (...) -> Export Artifact. You should see export options for TFLite and CoreML, together with other formats such as Tensorflow, PyTorch, and ONNX.
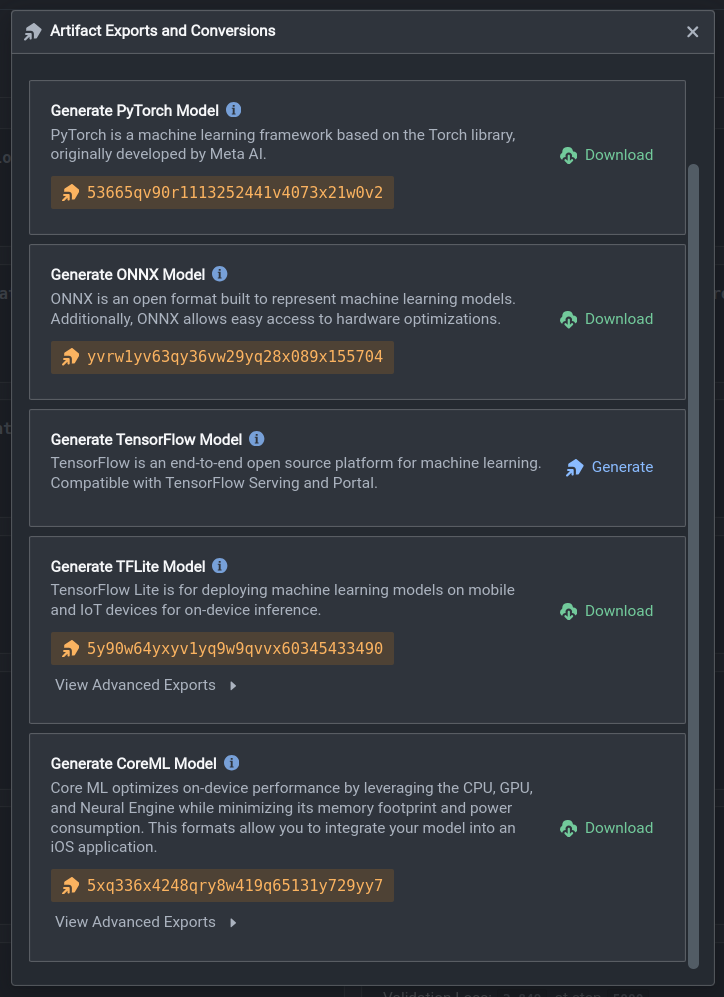
If you wish to export the original model in FLOAT32 precision, simply click on the Generate button next to your preferred model format. If a quantized model is desired, click on the View Advanced Exports button to bring up the advanced export options menu. Under the quantization section, you can select the quantization precision, FLOAT16 or INT8. Finally, click on Generate Advanced Export to export your quantized model.
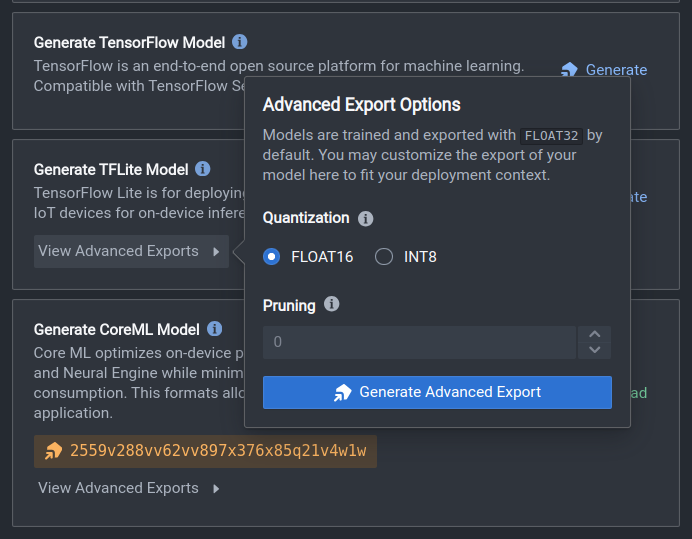
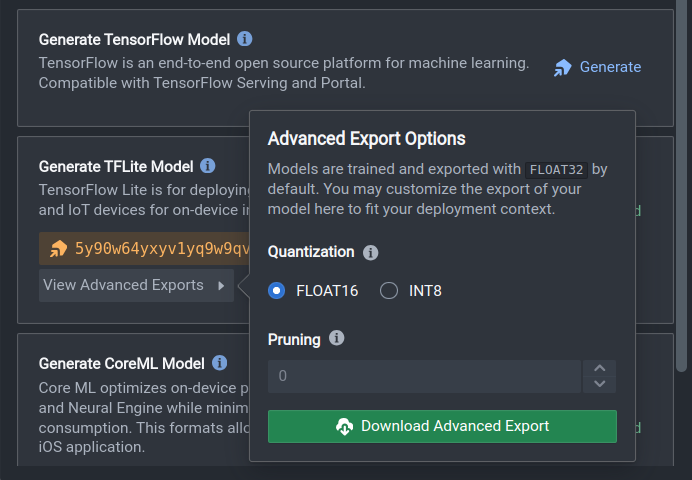
Once your model has successfully been quantized and exported (this may take up to 15 minutes), click on the Download Advanced Export button to save your model to your local filesystem. Alternatively, you can leverage our Python SDK to convert and download your model.
Quantization Modes
Quantization is currently supported for TFLite and CoreML model formats. If you would like your model quantized in a different model framework, please Contact Us for more details.
| Precision | TFLite | CoreML | Tensorflow | PyTorch | ONNX |
|---|---|---|---|---|---|
| FP32 (default with no quantization) | ✅ | ✅ | ✅ | ✅ | ✅ |
| FP16 | ✅ | ✅ | ❌ | ❌ | ✅ |
| INT8 | ✅ | ✅ | ❌ | ❌ | ✅ |
Common Questions
Why did my model accuracy drop after quantization?
The loss of precision during quantization, especially for INT8, can slightly affect model accuracy. If your hardware architecture is not limited to integer precision, we would recommend quantizing your model to FLOAT16 instead, as there will be negligible impact to the model accuracy.
Why is my model taking a longer time to make predictions after quantization?
Each quantization format is most compatible with specific hardware architectures. For example, running a FLOAT16 quantized model on CPU will be slower than running the original FLOAT32 model. This is because CPUs are not designed to run operations in FLOAT16 precision. This will cause the model to quantize and dequantize between the two precisions for each node for compatibility, incurring additional computations during inference. We recommend investigating the most suitable precision for your desired hardware architecture before making the decision to quantize your model.
Is there a way to finetune the quantized model to negate the impact on model accuracy?
We are developing support for static quantization (running calibration with a representative dataset), as well as Quantization-Aware Training to help the model become more robust to the effects of quantization. If you would like to beta-test these features, please Contact Us for more details.
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
Updated 10 months ago