
Module : Model
Model Selection and Options
We understand that your projects may have different accuracy requirements, and you may (or may not) be willing to trade accuracy for computational complexity. Therefore we have provided 28 model architectures (and more in the future) ranging from lightweight to highly complex models. Selecting the appropriate model for your use case can help you improve time efficiency and computational cost while balancing high accuracy. The impact is further detailed in Improving Model Performance.
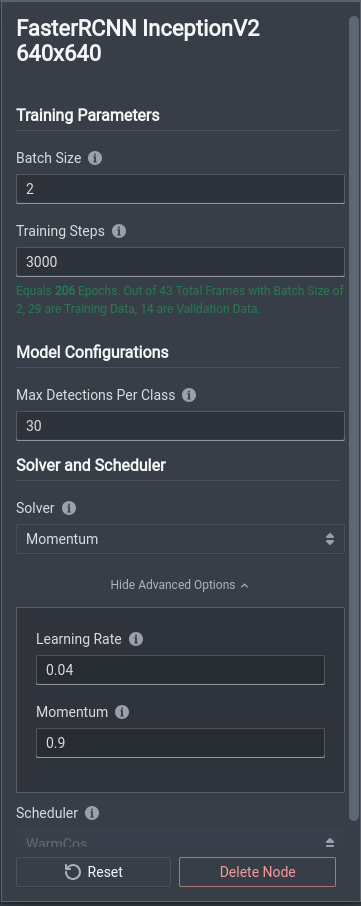
Model Module Options (click to enlarge)
Each model also has options for training parameters.
| Options | Input | Description |
|---|---|---|
| Batch Size | Any non-negative power of 2, e.g. 8 | Number of images or pieces of visual data that your model sees and trains upon at each training step. Your dataset is split up into batches of your predetermined batch size and trains on each batch. |
| Training Steps | Any non-negative integer, recommended to be at least 500 | Number of times your model trains on your dataset. Each step corresponds to training on a single batch determined by your batch size. The number of training epochs is also shown in green, which indicates the number of times your model trains over your whole dataset. |
| Max Detections Per Class | Any non-negative integer | Upper bound for the maximum number of instances per class that the model can make, so that the model can limit the list of possible output predictions. |
Advanced Options
There are also advanced options available for tuning specific hyperparameters.
| Options | Input | Description |
|---|---|---|
| Solver / Optimizer | Choice of Momentum, SGD, and Adam depending on the model architecture. | Algorithm designed to efficiently update the weights of a model during training, typically using gradient descent. |
| Learning Rate | Any real number between 0.0001 (1e-5) and 0.1 (1e-1). | Step size at which a model's weights are updated during the training process, effectively controlling how quickly or slowly a model learns from its training data. Larger values may quicken the process, but may suffer from non-convergence. Smaller values result in slower convergence, but training results may be sub-optimal if the optimization gets stuck in a local minimum. |
| Momentum | Any real number between 0 and 1 | Technique used to accelerate the convergence of the training process by smoothing out the variations in the gradient updates over time. |
| Scheduler | WarmCos (more options coming soon!) | Technique used to dynamically adjust the learning rate during the training process. It can help to avoid issues like slow convergence, oscillations, and overshooting the optimal parameter values. |
Checkpoint Selection
If you have previously trained models in your project, you can choose checkpoint weights created from any of those trainings to use as the initial weights for your new training.
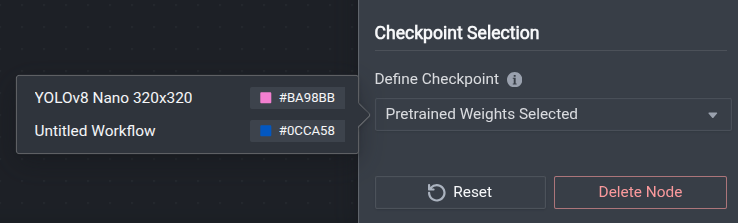
Note that only previous trainings that utilized the same model architecture as your current workflow will be shown in the selection list. Re-using weights across different model architectures is not supported.
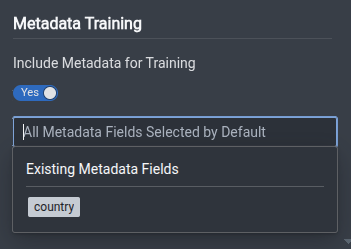
Training With Metadata
Metadata training is only supported for HGNetv2 (Classification) and D-FINE (Object Detection) architectures. If you want to enable this feature for other model architectures, please Contact Us.
If you have image-level metadata attached to your assets (such as geolocation, timestamps, etc.), you can incorporate them when training your model. The metadata is fused with the image feature representations, providing more context to the model during the learning process.
General Model Selection Tips
In general, models with larger dimensions on the end of the name imply more robust, complex models that are capable of taking in more data and thus more capable of learning more complex features for prediction. If you need higher accuracy and more complexity for your use case, then you should opt for higher dimensionality. However, if compactness and quicker training and inference is more important to you, then you should consider smaller dimensions.
When model names include names like ResNet, MobileNet, or InceptionV2, these represent different backbone models that are responsible for extracting image features such that the rest of the model can utilise these features for their own different processes. As a general trend of the same idea as the above paragraph, MobileNet is the most compact, ResNet is in the middle, and the number next to it, like 50 in ResNet50 indicates how many layers the model has, so the higher the number, the more complex it is. The most complex and robust is InceptionV2.
Model outputs differ based on the task that they are designed to solve. Datature currently offers models for the following tasks:
| Task | Description | Output |
|---|---|---|
| Classification | Classifies images with tags. | Outputs class tags. |
| Multiclass Classification | Classifies images with not mutually exclusive tags. | Outputs a subset of class tags. |
| Object Detection | Identifies objects in an image with bounding boxes and class tags. | Outputs bounding box coordinates and a class tag for each detected instance. |
| Semantic Segmentation | Used to describe which regions of pixels correspond to specific classes. | Outputs a mask array where each pixel has a value that is associated to a class. |
| Instance Segmentation | Used to describe which regions of pixels correspond to individual class instances. | Outputs a list of polygons with their associated class. |
Models
HGNetv2 Classification
| Architecture | Resolution | |||||
|---|---|---|---|---|---|---|
| HGNetv2 B0 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B1 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B2 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B3 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B4 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B5 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
| HGNetv2 B6 | 80x80 | 320x320 | 640x640 | 1280x1280 | 1680x1680 | 1920x1920 |
YOLOv8
YOLOv8 is an extension and improvement upon previous versions of the YOLO family of algorithms that is known for their real-time object detection capabilities. YOLOv8 builds upon the concepts of the original YOLO algorithm, aiming to improve both accuracy and speed. It incorporates advancements such as feature pyramid networks, spatial attention modules, and other architectural improvements to enhance the detection performance.
| Architecture | Classification | Object Detection | Segmentation | Keypoint Detection |
|---|---|---|---|---|
| YOLOv8 Nano | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| YOLOv8 Small | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| 2048x2048 | 2048x2048 | |||
| YOLOv8 Medium | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| YOLOv8 Large | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | ||
| YOLOv8 Xtra | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 |
YOLOv11
YOLOv11 is an extension and improvement upon previous versions of the YOLO family of algorithms that is known for their real-time object detection capabilities. YOLOv11 builds upon YOLOv8 by adding additional modules to improve on accuracy while still maintaining latency.
| Architecture | Classification | Object Detection | Segmentation | Keypoint Detection |
|---|---|---|---|---|
| YOLOv11 Nano | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| YOLOv11 Small | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| 2048x2048 | 2048x2048 | |||
| YOLOv11 Medium | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| YOLOv11 Large | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| YOLOv11 Xtra | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 |
YOLO26
YOLO26 is an extension and improvement upon previous versions of the YOLO family of algorithms that is known for their real-time object detection capabilities. YOLO26 builds upon the concepts of the original YOLO algorithm, aiming to improve speed primarily, by simplifying architecture and remove the necessity of NMS.
| Architecture | Classification | Object Detection | Segmentation | Keypoint Detection |
|---|---|---|---|---|
| YOLO26 Nano | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| 2560x2560 | ||||
| YOLO26 Small | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| 2560x2560 | ||||
| YOLO26 Medium | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | 1920x1920 | |
| 2560x2560 | ||||
| YOLO26 Large | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | ||
| 2560x2560 | ||||
| YOLO26 Xtra | 320x320 | 320x320 | 320x320 | 320x320 |
| 640x640 | 640x640 | 640x640 | 640x640 | |
| 1280x1280 | 1280x1280 | 1280x1280 | 1280x1280 | |
| 1600x1600 | 1600x1600 | 1600x1600 | 1600x1600 | |
| 1920x1920 | 1920x1920 | 1920x1920 | ||
| 2560x2560 |
RetinaNet Object Detection
| Architecture | Resolution |
|---|---|
| RetinaResNet50 | 640x640 |
| 1024x1024 | |
| RetinaResNet101 | 640x640 |
| 1024x1024 | |
| RetinaResNet152 | 640x640 |
| 1024x1024 | |
| Retina MobileNetV2 | 320x320 |
| 640x640 |
RetinaNet is a one-stage object detection model that utilises a focal loss function to address class imbalance in the training dataset. It has strong performances with dense and small scale objects.
FasterRCNN Object Detection
| Architecture | Resolution |
|---|---|
| FasterRCNN ResNet50 | 640x640 |
| 1024x1024 | |
| FasterRCNN ResNet101 | 640x640 |
| 1024x1024 | |
| FasterRCNN ResNet152 | 640x640 |
| 1024x1024 | |
| FasterRCNN InceptionV2 | 640x640 |
| 1024x1024 |
Faster R-CNN introduces a Region Proposal Network (RPN) that shares convolutional features with the detection network, enabling low-cost region proposals. Further, they merge this RPN with Fast R-CNN (another single end-to-end unified object detection network for quick object detection) to achieve high quality, rapid object detection results.
EfficientDet Object Detection
| Architecture |
|---|
| EfficientDetD1 640x640 |
| EfficientDetD2 768x768 |
| EfficientDetD3 896x896 |
| EfficientDetD4 1024x1024 |
| EfficientDetD5 1280x1280 |
| EfficientDetD6 1408x1408 |
| EfficientDetD7 1536x1536 |
EfficientDet is another object detection model which uses optimizations and scalable tweaks rather than additional modules to improve object detection. This is a model that is advantageous due to its model efficiency and ability to scale adaptively.
YOLOv4 Object Detection
| Architecture | Resolution |
|---|---|
| YOLOv4 DarkNet | 320x320 |
| 640x640 |
YOLOv4 is one of the newer one-stage object detection models running on DarkNet, which has achieved more improvements in the tradeoff in speed and accuracy of detection.
YOLOX Object Detection
| Architecture | Resolution |
|---|---|
| YOLOX Small | 320x320 |
| 640x640 | |
| YOLOX Medium | 320x320 |
| 640x640 | |
| YOLOX Large | 320x320 |
| 640x640 |
YOLOX is an anchor-free version of YOLO, with a simpler design but better performance that makes several modifications to YOLOv3.
YOLOv9 Object Detection
| Architecture | Resolution |
|---|---|
| YOLOv9 Compact | 320x320 |
| 640x640 | |
| 1280x1280 | |
| 1600x1600 | |
| 1920x1920 | |
| YOLOv9 Extended | 320x320 |
| 640x640 | |
| 1280x1280 | |
| 1600x1600 | |
| 1920x1920 |
YOLOv9 is an improvement upon YOLOv8, aimed at using a different extension of architecture for improved performance.
DeepLabV3 Semantic Segmentation
| Architecture | Resolution |
|---|---|
| DeepLabV3 ResNet50 | 320x320 |
| 640x640 | |
| DeepLabV3 ResNet101 | 320x320 |
| 640x640 | |
| DeepLabV3 MobileNetV3 | 320x320 |
| 640x640 | |
| 1024x1024 |
DeepLabv3 is a semantic segmentation architecture with improvements to handle the problem of segmenting objects at multiple scales.
UNet Semantic Segmentation
| Architecture | Resolution |
|---|---|
| UNet ResNet50 | 320x320 |
| 640x640 | |
| UNet VGG16 | 320x320 |
| 640x640 |
U-Net is a semantic segmentation architecture. It consists of a contracting path and an expansive path that consider both typical features from a convolutional network and a progressively upsampled feature map to improve detail.
FCN Semantic Segmentation
| Architecture | Resolution |
|---|---|
| FCN ResNet50 | 320x320 |
| 640x640 | |
| FCN ResNet101 | 320x320 |
| 640x640 |
Fully Convolutional Network is a semantic segmentation architecture. It exclusively uses locally connected layers, such as convolution, pooling, and upsampling, and avoids the use of dense layers. This makes it faster to train and reduces parameter size.
MaskRCNN Instance Segmentation
| Architecture |
|---|
| MaskRCNN InceptionV2 1024x1024 |
MaskRCNN is Datature's instance segmentation model designed for predicting segmentation masks using RCNN as the base model.
👋 Need help? Contact us via{" "} website or{" "} email
<p>
🚀 Join our{" "}
<a href="https://joindatature.slack.com/join/shared_invite/zt-hv9xv84h-WYDFnU1clNM0eGW4SfQGGg#/shared-invite/email">
Slack Community
</a>
</p>
<p>
💻 For more resources:{" "}
<a href="https://www.datature.io/blog">Blog</a> |{" "}
<a href="https://github.com/datature">GitHub</a> |{" "}
<a href="https://www.datature.io/tutorials">Tutorial Page</a>
</p>
<p>
🛠️ Need Technical Assistance?{" "}
<a href="https://developers.datature.io/docs/adding-collaborators">
Connect with Datature Experts
</a>
{" "}
or chat with us via the chat button below 👇
</p>Updated 5 months ago