
Module : Dataset
Dataset Setup
For any workflow, a Dataset module is necessary. To create one, right-click on the blank canvas, scroll to Datasets and select the relevant Dataset that you want your model to utilize. To see the options, you can select the Dataset block and a side menu will appear on the right like below.
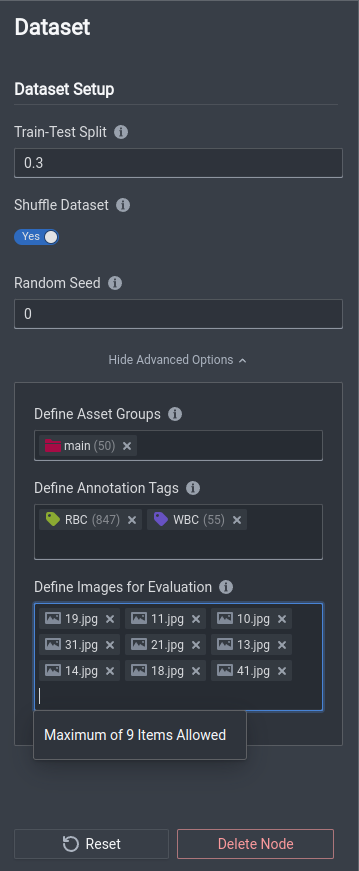
Once the module appears on the canvas, you can select the module and change the following settings.
| Options | Input | Description |
|---|---|---|
| Train-Test Split | 0.0 to 1.0 | Train-Test split refers to the size of the randomly selected proportion of data from your dataset that should be used for model evaluation. The other data not in that proportion is then used for the training. One should input some value between 0 and 1. |
| Shuffle Dataset | Enable/Disable | Shuffling a dataset refers to randomly ordering the data for use in the dataset, such that the model receives the same data but not always in the same order to increase variability and robustness. |
| Random Seed | Any non-negative integer i.e. 3338 | This is typically for experimental use to allow for reproducibility. If you set the Random Seed to the same value, the random generation or selection will be the same given all other variables and settings are the same. |
Advanced Options
| Options | Description |
|---|---|
| Define Asset Groups | Select Asset Groups that you want used for the training dataset, e.g. if you have asset groups main, Dataset 1, Dataset 2, where main usually contains all images and Dataset 1, Dataset 2 contain specific sets of images within the overall dataset, you can select the specific group(s) Dataset 1 and/or Dataset 2. |
| Define Annotation Tags | Select specific annotation tags that you want to train specifically, e.g. you have tags RBC,WBC, and Platelets and you want to train a model to only detect RBC and Platelets, you can select the corresponding tags here. |
| Define Images for Evaluation | Specify images by image file name which will subsequently be used for tools like Advanced Evaluation for Model Performance. This allows for finer control of how you evaluate models, and acts as a benchmark dataset. You can name up to 9 images for evaluation. |
Sliding Window Setup
This sliding window option allows for your images to be sliced into smaller crops to allow your model to focus on individual crops in your dataset.
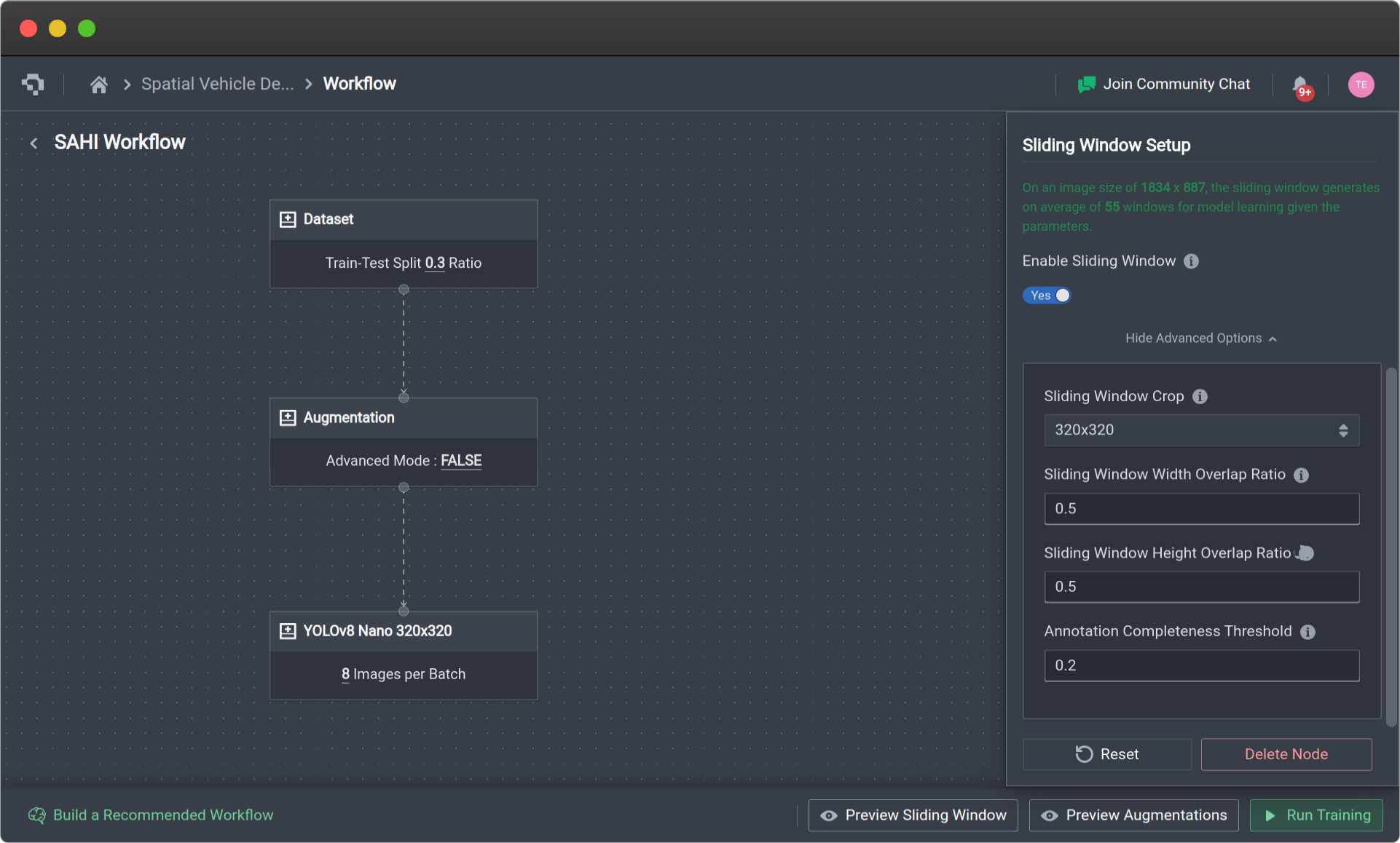
This facilitates your model in being able to detect relatively small objects and is well suited for image inputs with small objects or images with very high resolutions. To use the Sliding Window setup, select the toggle to Enable Sliding Window.
Advanced Options
Sliding Window also has the following advanced options which can be found through Show Advanced Options:
| Options | Values | Description |
|---|---|---|
| Sliding Window Crop | 320x320 , 640x640, 960x960, 1024x1024, 1280x1280, 1600x1600, 1920x1920 | This determines the size of the sliding window that is applied. As these will be used to train your models, you will be limited to the specific resolutions that can be fed into the models. |
| Sliding Window Width Overlap Ratio | 0.1-0.95 | This determines the proportion of the crops that overlap horizontally with each other. |
| Sliding Window Height Overlap Ratio | 0.1-0.95 | This determines the proportion of the crops that overlap vertically with each other |
| Annotation Completeness Threshold | 0.0-1.0 | This removes sliced annotations whose Intersection over Union (IoU) compared to their original annotation is below the threshold. |
Preview Sliding Window
You can preview your sliding window setup as well by selecting Preview Sliding Window, which will appear on the bottom of the page after you enabled the sliding window option.
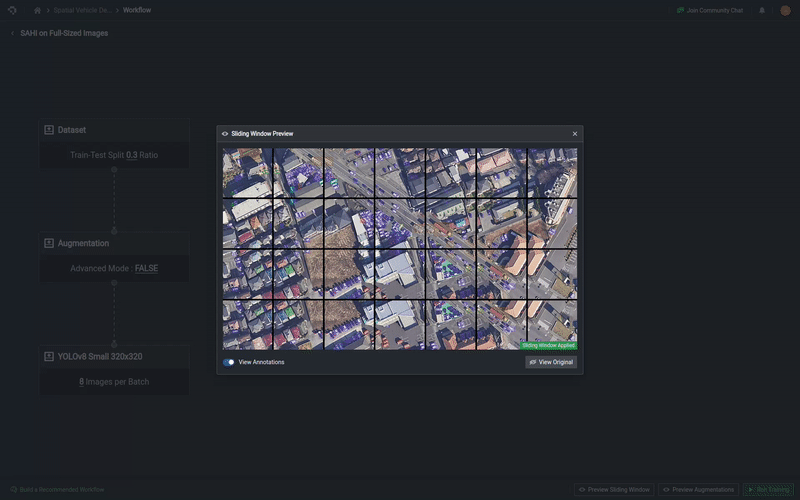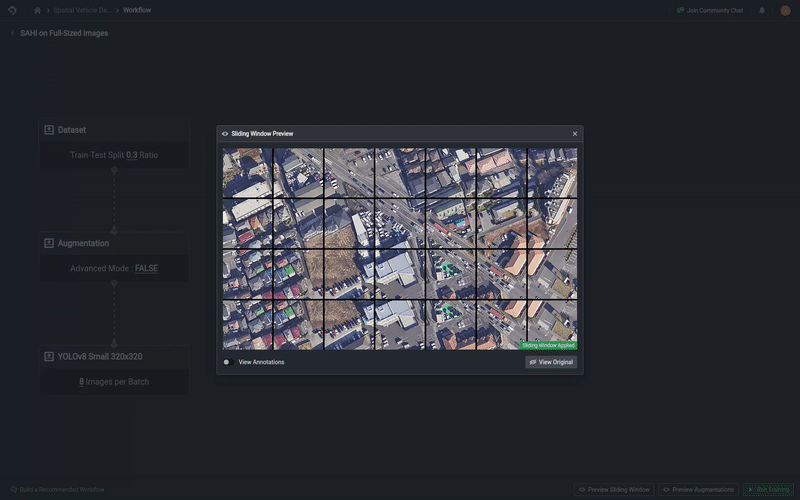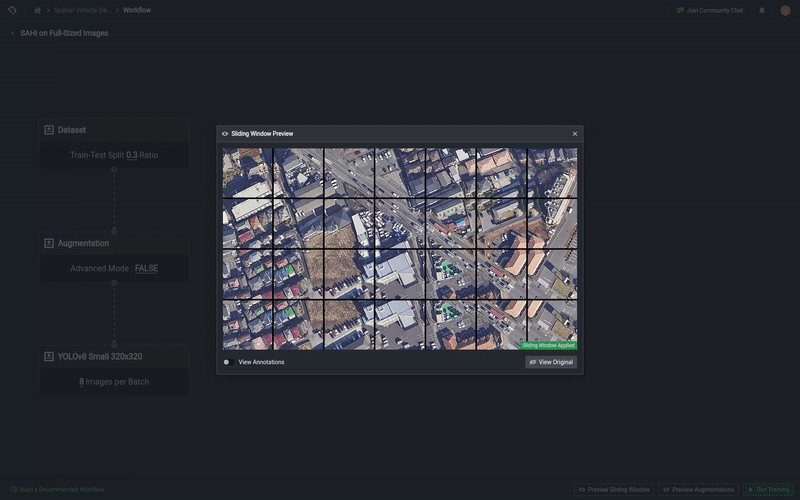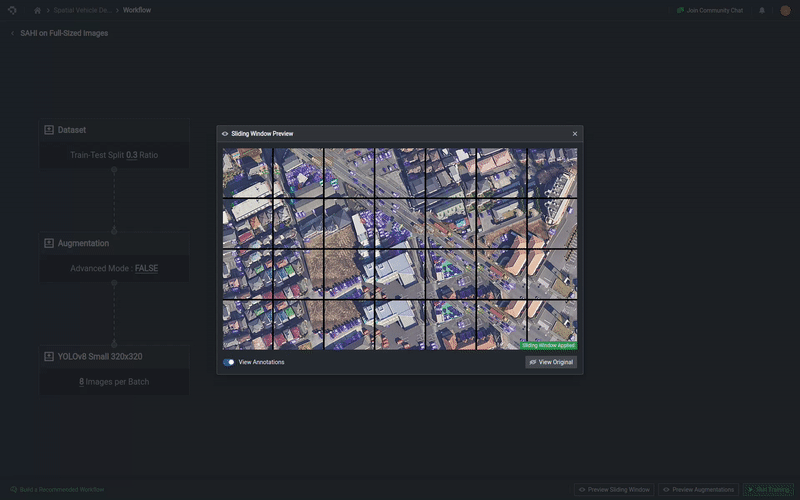
To learn more about why you might want to use sliding windows, you can read this blog here!
Class-Balancing Setup
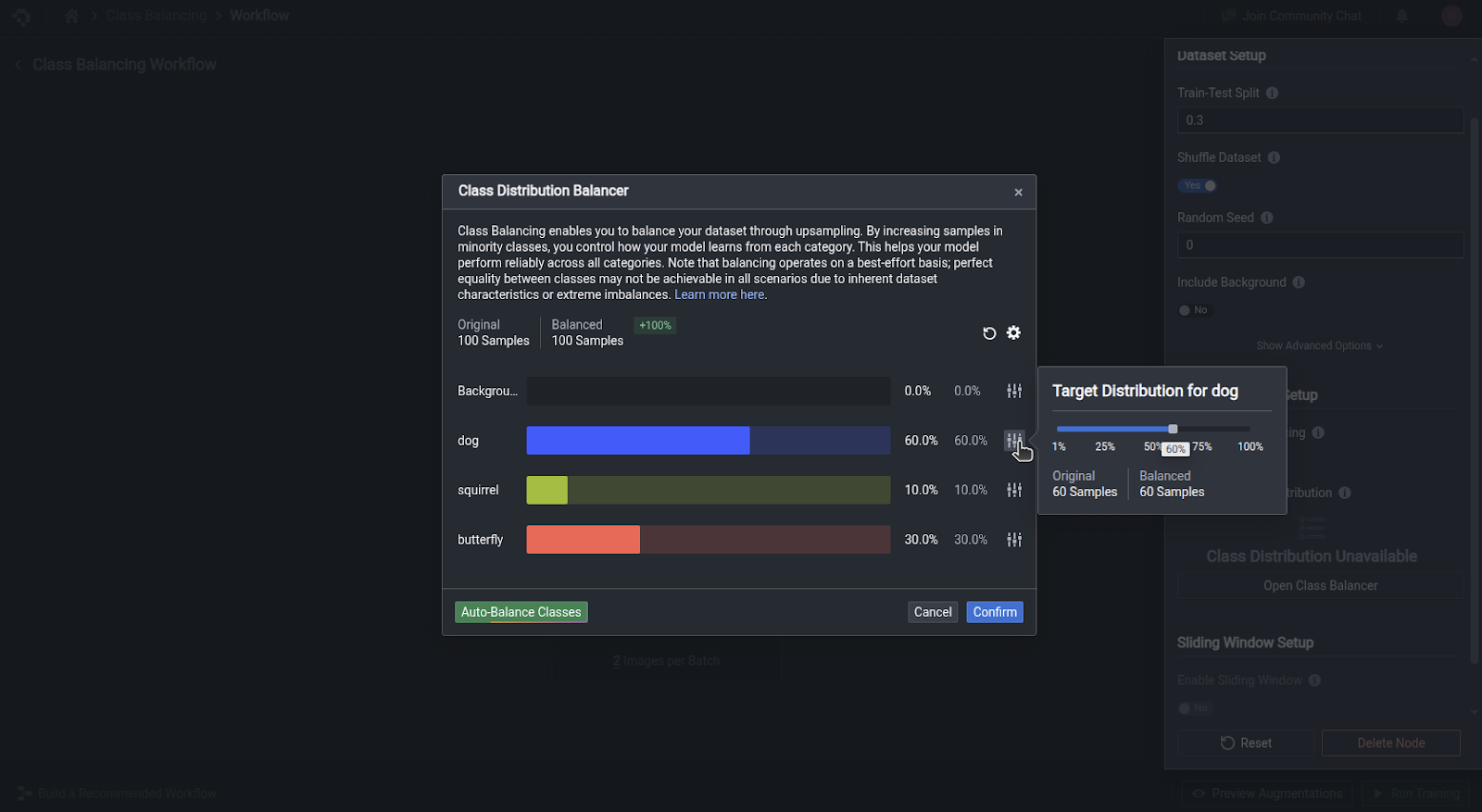
The class balancing option mitigates poor model performance on rare classes by automatically identifying and duplicating instances of the rare classes in your dataset.
To enable this feature, simply toggle the Enable Class Balancing button.
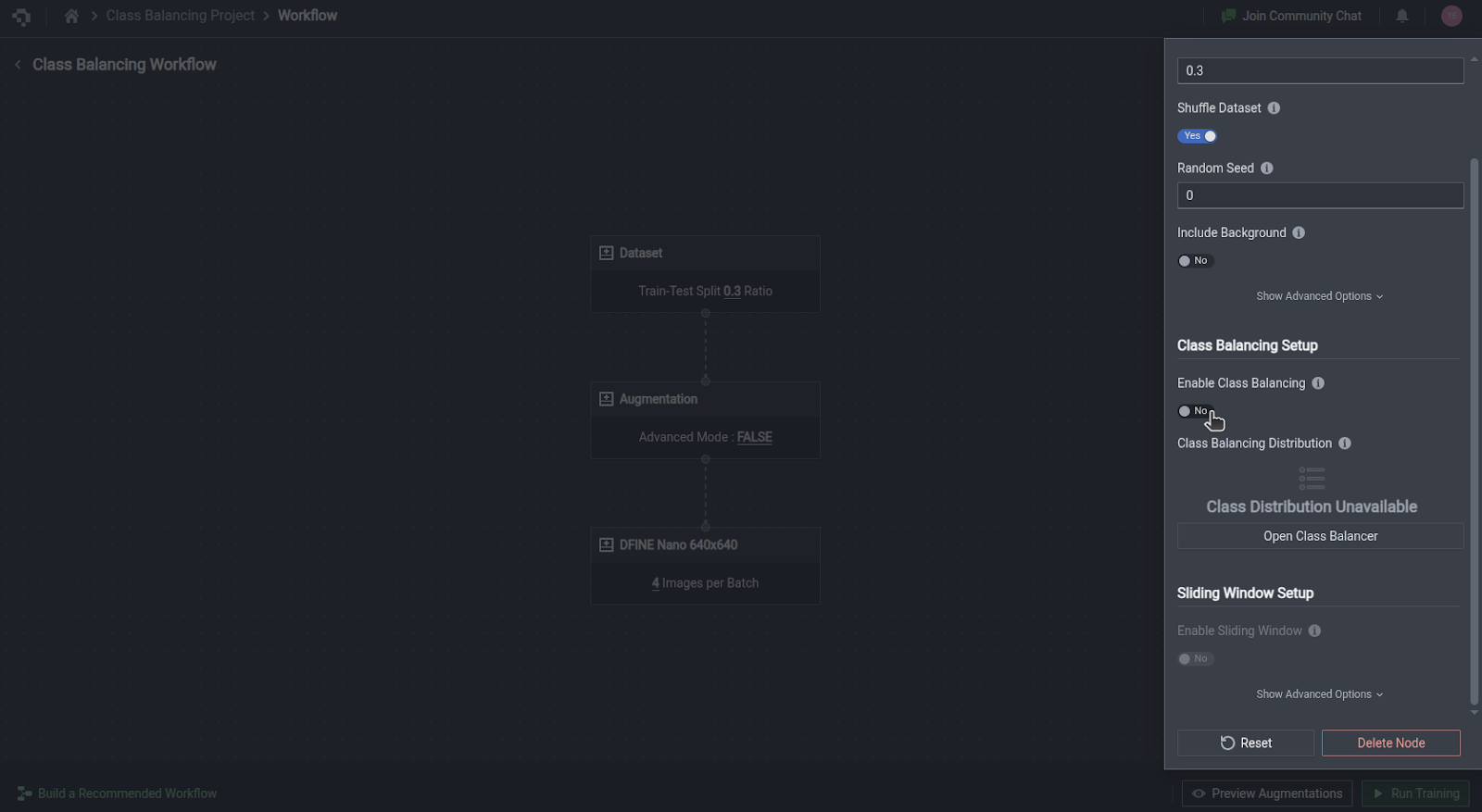
This will display an Open Class Balancer option. Clicking this button pops out a card showing the current distribution of classes in your dataset. Click on the Auto-Balance Classes button to automatically recalculate a more balanced distribution of instances in each class. The new percentages will be respected by duplicating images containing lower-represented classes during model training.
Note that the current duplication algorithm works on an image-level, so higher-represented classes may be duplicated as well if they are present in the images identified for duplication. Hence, it is normal that the resultant distribution is not exactly equal.
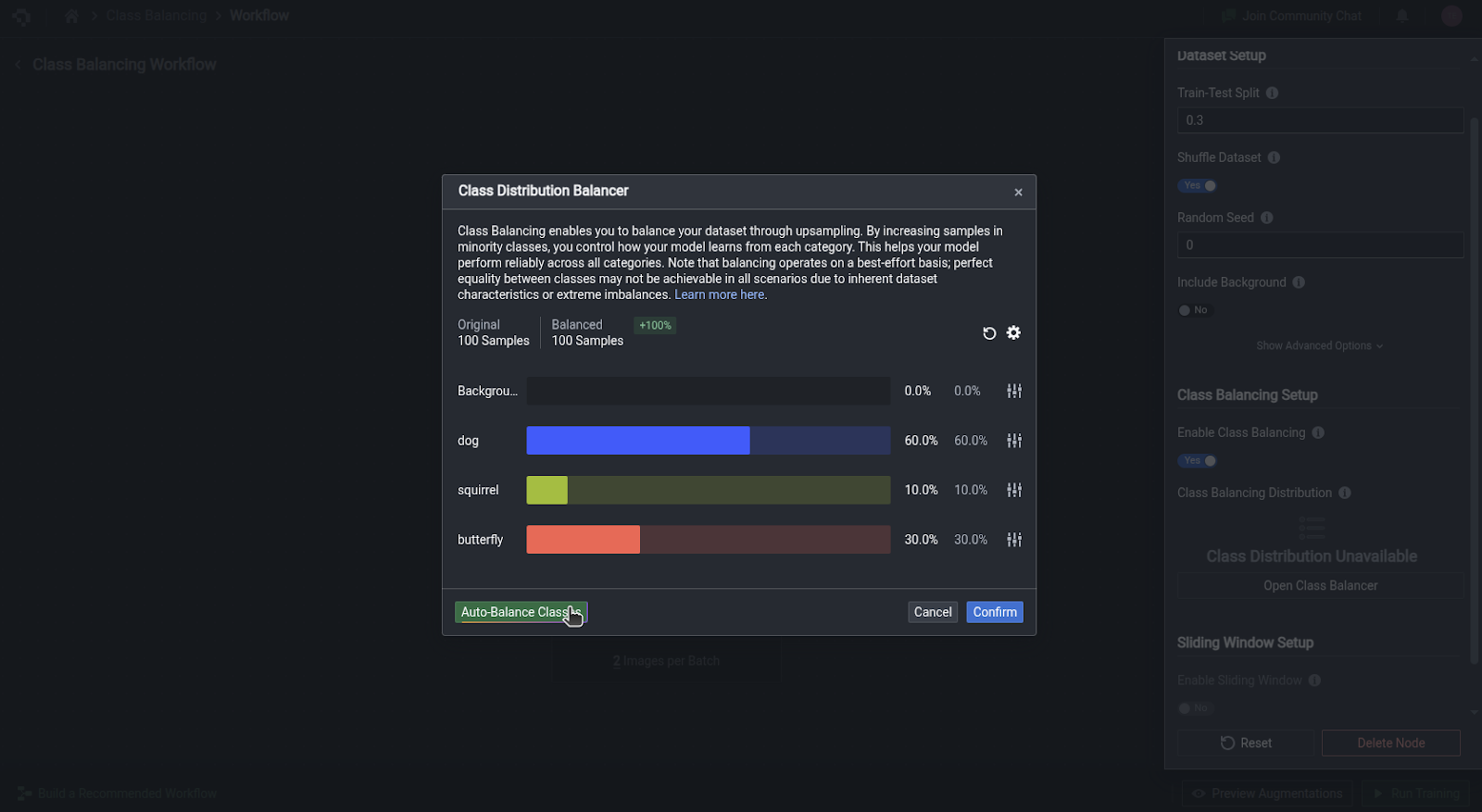
If you want to manually adjust the target distribution of each class, you can adjust the slider accordingly. Do note that the other classes will automatically be scaled accordingly, so that the total distribution remains at 100%.
Common Questions
How do I decide what Train-Test Split to select?
Literature typically suggests some number between 0.2 and 0.3. However, it depends on your use case and the results of your training. If after Evaluating Model Performance or Generating Predictions, you notice that the evaluation metrics are not representative of either training or test inference, you may want to increase the size of your test split to determine whether your model is evaluating correctly.
Will we be able to use different datasets?
You can now use these advanced options to select groups of data within your dataset for training and select specific images for evaluation as well.
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
Updated 10 months ago