
Post-Training Model Pruning
What is Model Pruning?
Model pruning removes unimportant parameters from a deep learning model to reduce the model size and enable more efficient model inference. As these parameters are being removed, this may result in some degradation of the model’s inference performance, hence it should be performed with care.
Datature Nexus currently supports unstructured pruning with a balance of local and global pruning. This means that individual weights or clusters of weights are zeroed out, with no change to the overall structure of the model architecture. This helps to maximize compatibility with all our supported inference modes and integrations with supported devices.
How to Perform Model Pruning on Nexus
You will first need to train a model on Nexus. Once that’s done, navigate to the Artifacts page where you can view the model checkpoints that have been saved. When you have chosen the model checkpoint you wish to export, click on the three dots (...) -> Export Artifact. You should see export options for a variety of model formats, including Tensorflow, PyTorch, ONNX, LiteRT (TFLite) and CoreML.
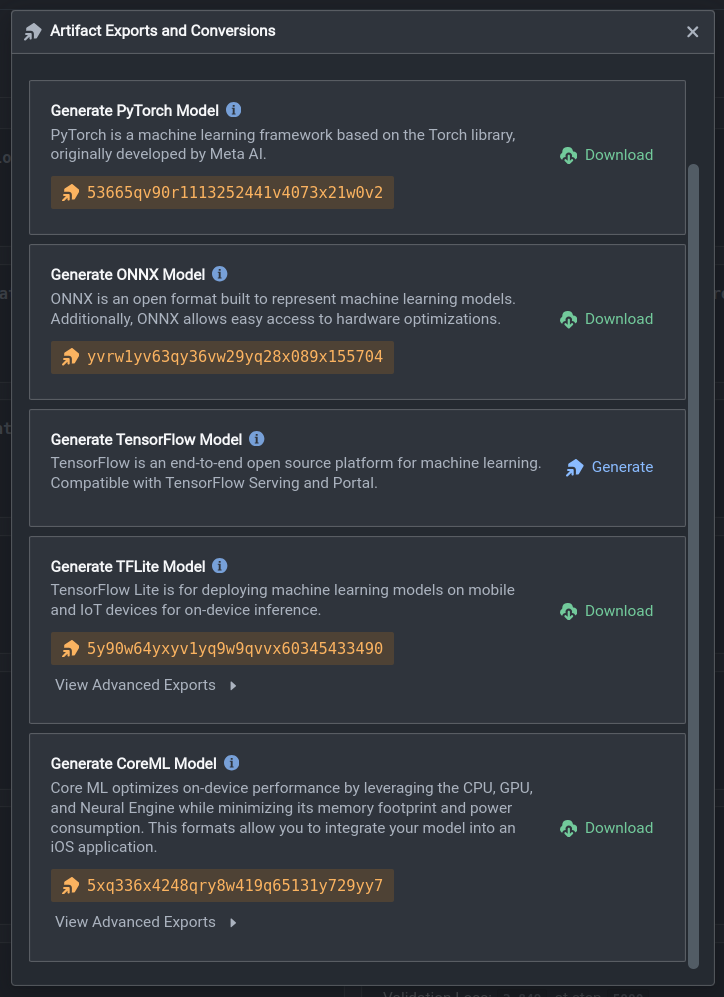
If you wish to export the original model without any pruning, simply click on the Generate button next to your preferred model format. If a pruned model is desired, click on the View Advanced Exports button to bring up the advanced export options menu. Under the pruning section, you can select the pruning ratio from 10% all the way to 90%. This is an upper bound on the percentage of weights that could potentially be zeroed out in the model during the pruning process. Finally, click on Generate Advanced Export to export your quantized model.
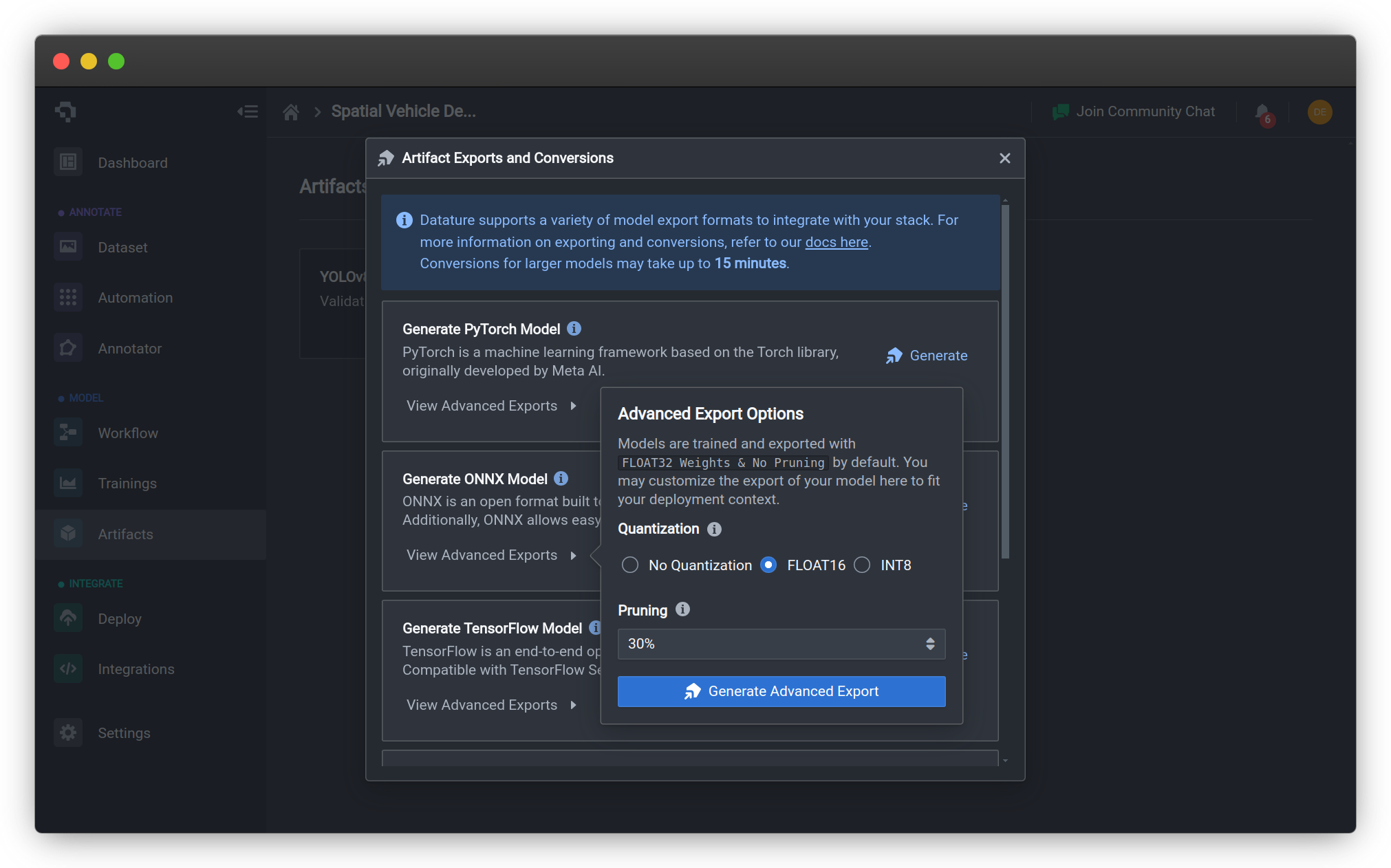
Once your model has successfully been pruned and exported (this may take up to 15 minutes), click on the Download Advanced Export button to save your model to your local filesystem. Alternatively, you can leverage our Python SDK to convert and download your model.
Model Support
Pruning is currently supported for all models except Tensorflow Object Detection models*. Pruned models can be exported in any of the model formats we support, as listed in the table of support below.
*Unsupported models include MobileNet, EfficientDet, ResNet, YOLOX, FasterRCNN, and MaskRCNN.
Object Detection
| Model Type / Export Format | Tensorflow | PyTorch | ONNX | LiteRT (TFLite) | CoreML |
|---|---|---|---|---|---|
| YOLOv4 | ✅ | ✅ | ✅ | ✅ | ✅ |
| YOLOv8 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MobileNet | ❌ | ❌ | ❌ | ❌ | ❌ |
| EfficientDet | ❌ | ❌ | ❌ | ❌ | ❌ |
| ResNet | ❌ | ❌ | ❌ | ❌ | ❌ |
| YOLOX | ❌ | ❌ | ❌ | ❌ | ❌ |
| FasterRCNN | ❌ | ❌ | ❌ | ❌ | ❌ |
Segmentation
| Model Format | Tensorflow | PyTorch | ONNX | LiteRT (TFLite) | CoreML |
|---|---|---|---|---|---|
| YOLOv8-SEG | ✅ | ✅ | ✅ | ✅ | ✅ |
| DeepLabV3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| FCN | ✅ | ✅ | ✅ | ✅ | ✅ |
| UNet | ✅ | ✅ | ✅ | ✅ | ✅ |
| MaskRCNN | ❌ | ❌ | ❌ | ❌ | ❌ |
Classification & Keypoint Detection
| Model Format | Tensorflow | PyTorch | ONNX | LiteRT (TFLite) | CoreML |
|---|---|---|---|---|---|
| YOLOv8-CLS | ✅ | ✅ | ✅ | ✅ | ✅ |
| YOLOv8-Pose | ✅ | ✅ | ✅ | ✅ | ✅ |
Common Questions
Why can I not use advanced exports?
The model you've trained was prior to our model optimization update and is not compatible with the model optimization flow. You can choose a model that is compatible based on the above tables to get a trained artifact that can utilize the model optimization.
Why did my model accuracy drop after pruning?
Though pruning aims to zero out weights deemed as unimportant, these weights may still contribute slightly to the decision-making process of the model, resulting in a slight dip in accuracy. To negate this effect, we are developing support for finetuning pruned models, as well as Pruning-Aware Training. If you would like to beta-test these features, please Contact Us for more details.
👋 Need help? Contact us via website or email
🚀 Join our Slack Community
💻 For more resources: Blog | GitHub | Tutorial Page
🛠️ Need Technical Assistance? Connect with Datature Experts or chat with us via the chat button below 👇
Updated 11 months ago